
my aim for this project was to create a vocal synthesizer in C++. This involved:
- understanding the physical mechanisms and perceived frequency content of the
human voice.
- studying the previous physical and spectral models used to synthesize vocals.
- learning the basics of the the synthesis toolkit in C++ (STK).
- apply what i've learned, and design a MIDI-compatible monosynth for vocal sounds.
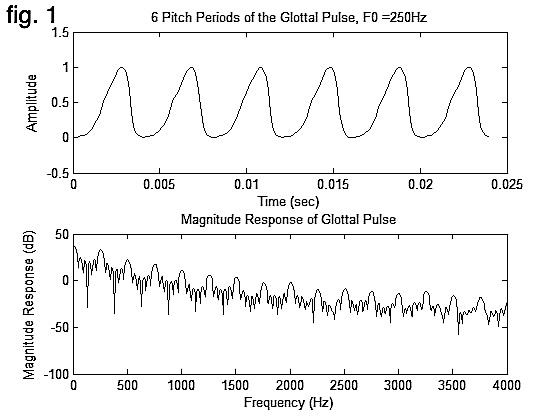
the first step of my project involved developing a better understanding of the human
voice, and researching possible methods for synthesizing vocal sounds. the human
voice produces sounds via a few methods. when the vocal folds vibrate, they produce a
"glottal pulse wave" (fig. 1). this wave has relatively even harmonic content across the
frequency spectrum, with a slight dip in the higher frequencies. in addition, turbulence
that occurs as airflow is constricted at various points in the vocal tract (i.e. between
the top and bottom teeth) produces fricatives. these sounds are then filtered by the vocal
tract, the shape of which is manipulated to produce resonant peaks in the frequency
response of the tract. the tongue, soft palette, and lips all play a crucial role in the
manipulation of these peaks, which are commonly referred to as formants.
generally, when recreating existing sounds, synthesis methods can be grouped into 2
main categories: spectral models and physical models. spectral models aim to reflect
the frequency content of a sound most accurately, and are generally computationally
cheaper than physical models. physical models aim to synthesize sounds via methods
that reflect the physical mechanisms utilized in the production of the modeled sound.
the advantage of physical models is that control parameters are inherently mapped to
the "controls" of the modeled sound. in practice, synthesizers that model existing
sounds are generally part physical model and part spectral model, to maximize both
realism and computational efficiency.
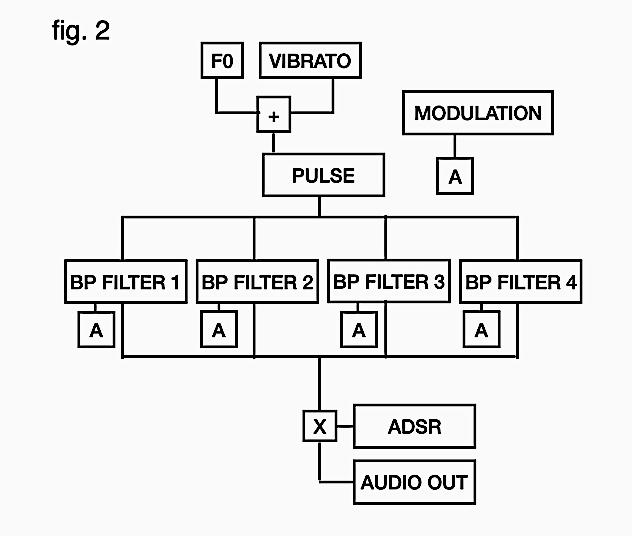
after prototyping a few different synthesis methods in matlab, i settled on a
source-filter model implemented with a band limited impulse train and 4 bandpass
filters in parallel. a source-filter model separates the source of a sound sound
(the vocal folds), from the resonant cavity that shapes the frequency spectrum of said
sound (the vocal tract). a block diagram of the signal flow of the synth can be seen
above (fig. 2).
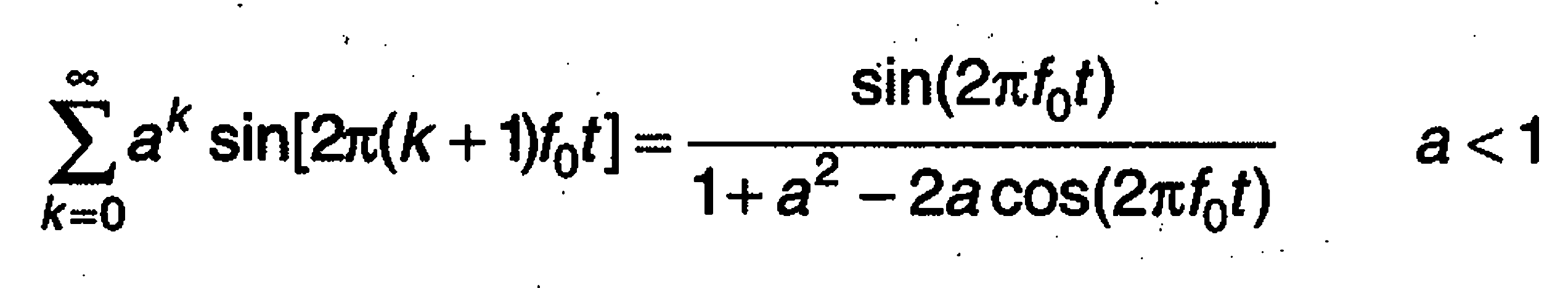
to realize the pulse wave used in the synthesizer, i referenced the formula below (dodge and jerse, 1997, pg. 164). the a-value scales each consecutive harmonic according to the fundamental frequency, so that the aliased harmonics are scaled enough to be unnoticeable in the output signal. in order to express the a-value as a function of the fundamental frequency, i took measurements at frequencies spaced logarithmically across the spectrum, and then fit an exponential decay curve to the measured points. i encountered some issues regarding the gain of the output signal as the frequency varied, so i applied a variable normalization, which i obtained via a similar process.
after being generated, the pulse wave is passed through 4 resonant bandpass filters, with variable cutoff frequencies and resonances. i used the resonance filter formula from the mumt 307 class notes. they are second order infinite impulse response filters, with numerator and denominator coefficients defined by:
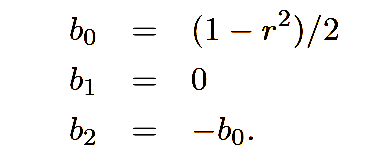
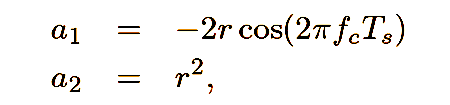
the variable r is pole radius, ts is the sampling period, and fc is the center frequency of the filter. each filter has a minimum and maximum center frequency, and the r-value of each filter is ensured to be less than 1 (to avoid continuous oscillation). the range of center frequency is wider for the filters that occupy the upper end of the frequency spectrum, and narrower for the filters that occupy the lower end of the frequency spectrum. i found that, from a control and use perspective, this makes most sense, as it aligns with the human logarithmic perception of frequency.
when running vowl, the user has the ability to manually set parameters, or to map them to an lfo, adsr, or midi ccs. this is possible via the synthesis parameters submenu. the properties of the lfo, modulation adsr, and amplitude adsr can be edited in the modulation parameters submenu. midi ccs are stored in a 128 element vector, with each element corresponding to a midi cc number. when a control change happens, the new value is stored in the correct element. any synthesis parameter that takes into account said midi cc will consider this change when the parameter is updated. all of the parameters except the frequency of the pulse are set to be updated once per buffer, to minimize the computations required every time an output sample is computed.

my biggest obstacle with this project was that my programming experience is quite limited. a lot of my code could probably be optimized, and the synthesizer is most definitely not ready to present to a user who has not had any previous explanation. however, throughout the process of designing this synth, i learned a lot about c++ and synthesis, and i feel that it's a good start to a potential vowl 2.0.